Scaling problems are rooted in the algorithms themselves
Consider the problem of car detection. In this model, the goal is simply one of determining whether there are cars in an image or not. A neural network will detect an object and assign a label “car” if it is a car. To train this neural network, you pass in 100-200 images of cars with bounding boxes over the cars labeled “car”. But with the limited number of images provided for training, we would soon realize that the algorithm can only generalize slightly and would have a tough time classifying cars in a wide range of scenarios that differ from those presented in training.
 Bounding boxes classifying cars in an image
Bounding boxes classifying cars in an image
Source: Zapp2Photo/Shutterstock
And that is where the problem lies. In machine learning, usually more is better. The more data to analyze and the more neural network parameters in the algorithm, the more compute power is needed to run it. Give 100,000 images of cars instead of the 100-200 from earlier and the car classification algorithm will leap to a 95% accuracy level. But that increase in data and model complexity comes at a cost – the model takes longer to run and is GPU/CPU bound.
This cannot scale nor is it realistic. Imagine if Google Chrome used 80% of your GPU power, CPU power, and RAM just to let you surf. Imagine if Instagram asked you to upload 100 images of yourself to help its AI with classification. Imagine if a video game’s AI was so advanced that the download size for the actual game became larger than the game disk in a console.
The technology seems ready for faster adaptation into commercial solutions, but certain problems in data curation and model deployments persist. As an example, one can now develop an algorithm that can take an image of a product and provide nutritional information within a matter of milliseconds. However, this is isolated to one’s phone and maybe a few others. A far more important question now arises: how can one get this into the hands of millions of grocery shoppers who would benefit from this and do so in a cost-effective manner, i.e. commercialize this technology at scale?
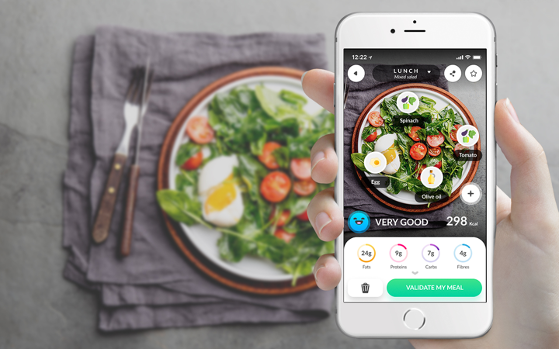 Foodvisor App
Foodvisor App
Courtesy: TechCrunch
A startup called Foodvisor worked on this idea but was limited in its initial launch. According to VentureBeat in 2018, “The app’s deep learning algorithm can identify 1,200 types of food…if the app makes an obvious mistake, users can correct it, thus adding information that can improve overall accuracy.” In this case, the app relied on user data to improve algorithm accuracy (also called dataset curation); the inherent problem was that it would take a very long time to reach a critical mass of users whose input would help in algorithm improvement. And even if the model did get better, how would it tradeoff dataset curation with quick model deployments?
These are all realistic problems with computer vision that MLOps aims to solve.
The state of the art in computer vision
We can trace the origins of computer vision to 1959, where the first digital image scanner was invented that transformed images into grids of numbers. About 20 years later, Kunihiko Fukushima built the Neocognitron, which was a precursor to CNNs (convoluted neural networks - the most common neural network structure for computer vision).
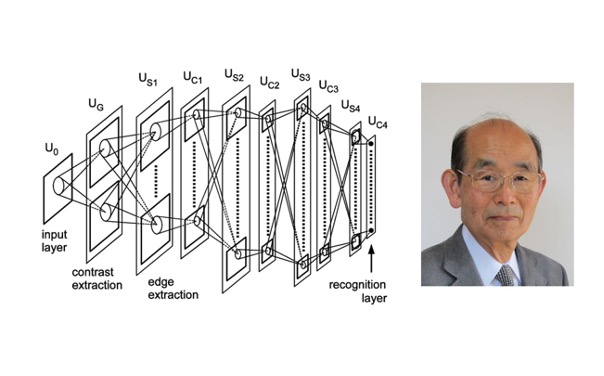 Kunihiko Fukushima and the Neocognitron
Kunihiko Fukushima and the Neocognitron
Image credit: Veronika Gladchuk
In 2001, two researchers at MIT created the first real-time face detection framework. The string of academic advances continued with the creation of ImageNet in 2007 by Dr. Fei Fei Li of Stanford University, which is a large dataset consisting of more than 14 million images. In 2009, the world started to see research departments at large companies such as Google use image recognition for autonomous driving. In 2011, computer vision techniques were used to help identify Osama bin Laden’s body after the raid in Abbottabad. Over the past decade, numerous AI startups and companies have been experimenting with using computer vision in public spaces and commercial products.
Leap and the net will appear
The field has evolved rapidly and has become very advanced. Most advanced models in computer vision have been trained in a supervised manner that requires hundreds and thousands of labeled and annotated images per object (e.g. cat, dog, human, or apple) being identified. However, in the past two years, self-supervision technology has taken the research community by storm. AI models are trained to predict the information already available in the input without explicitly providing the label for an input. For example, for a given pixel or a region in an image, a self-supervision task could be to predict nearby pixels or regions within the same image, or for a given image, another self-supervision task could be to randomize the pixels or regions and let an AI model generate the original image. Note that this information already exists for every image. We can train large pre-trained self-supervised computer vision models on theoretically every image present on the planet because we are not bound by the amount of labels or annotations available.
 Self-Supervised Learning: Learning to reconstruct original image from a randomized regions or pixels of an image
Self-Supervised Learning: Learning to reconstruct original image from a randomized regions or pixels of an image
Image credit: Matvii Kovtun [perfectial.com]
This idea of Self-Supervised learning in computer vision comes from the NLP community wherein Google BERT and OpenAI GPT models are trained to generate language without any explicit label (e.g. sentiment or topic) associated with the language being generated. Once these AI models are trained in a self-supervised manner then they can be used or fine-tuned for the actual task of object classification or sentiment detection requiring only a few labeled or annotated examples as opposed to hundreds or thousands of labels required earlier. This happens because with self-supervised learning, we make AI models understand the patterns in the data without having explicit labels about it and once the data and patterns are understood then the model has to merely update a few parameters for image classification or detection task. For supervised image classification, the Facebook AI research team has developed FixEfficientNet, which has a top-1 accuracy of 88.5% using a 480 million parameter neural network on the ImageNet dataset. For object detection, Google Brain developed Efficient-Det D7x, which received an average precision of 74.3% on the ImageNet dataset. For semantic segmentation, Nvidia’s team developed HRNet-OCR which has a mean IOU accuracy of 85.1%.
Not so state of the art
However, not all state of the art computer vision algorithms are foolproof. While they may be at the top of the list, there is still a lot of innovation left to do in order to reduce the number of instances where the algorithm gets fooled. For example, OpenAI’s CLIP, an algorithm intended to explore how AI systems learn to identify objects without close supervision on large datasets, is prone to what researchers called typographic attacks.

The apple of my i
Image Credit: OpenAI
In the example, the CLIP algorithm seems to be basing its decisions off of the text input as well as the image input but giving more bias towards the text. Researchers at OpenAI said, “The same ability that allows the program to link words and images at an abstract level creates this unique weakness.” More researchers can use models like CLIP to understand how neural networks learn and the extent to which data can be manipulated to maintain similar accuracies in classifications.
Moreover, although self-supervised learning requires a few labeled examples for a given downstream task as opposed to orders of magnitude of more traditional supervised counterparts, most of the self-supervised models are extremely large to fit inside the memory or are slow thereby making them harder to commercialize.
Commercialization of computer vision
State of the art advances in computer vision make it possible to deploy models to analyze extremely large amounts of real-world data. But even with declining costs in compute power and storage, and the availability of more tools to create datasets, it still takes longer for computer vision products to be deployed and commercialized. Before we discuss a potential method to reduce deployment times for machine learning models, we need to discuss the four drivers of computer vision commercialization:
- ML algorithms
- Data abundance
- Computational power
- Edge computing
ML algorithms
State of the art machine learning algorithms are becoming more computationally efficient and highly adaptable, but some of the more advanced models with high accuracy are expensive. Since 2006, Google has spent $3.9 billion on AI development. We have previously seen that some of the best models come out of Google Brain, Google’s AI department, partially because Google has the reach and money to spend on data acquisition, curation and model development.
Google’s valuation hovers around $1.2 trillion. Commercializing their AI and computer vision products has been successful thus far, with integration into their suite of web tools and smart home devices. Unfortunately, for an SMB wanting to commercialize computer vision algorithms, such resources do not come easily, if at all. Unlike standard development cycles, these companies need to hire data scientists to work on creating the ML model.
Data abundance
For specialized situations, creating a dataset requires tons of resources including time, data scrapers, and tools for dataset assessment. Once deployed in production, additional support for configuration and monitoring of the product or service is needed, especially for machine learning related problems. For small and medium businesses, this is a lot to handle, which is why they should consider MLOps.
Computational power
To address the computational power driver of commercialization, it is worth noting that computer vision algorithms naturally use a lot of compute. With a large number of images, the workload becomes intense and requires chips optimized for machine learning workflows. There are over a dozen new and existing companies with over $2B in funding that are focused on this problem by building AI chips. For example, ARM specializes in artificial intelligence enhanced computing. According to Wired magazine, ARM’s efforts focus on two areas: fitting software frameworks onto existing CPUs and creating an accelerator for intense workloads called a neural processing unit (NPU). Advancements in these two areas will improve computational efficiency and lead to less spending on computer power.
 AI enabled devices running ARM Ethos NPU
AI enabled devices running ARM Ethos NPU
Image Credit: ARM
Edge computing
Currently, most machine learning data is stored in the cloud, which poses a latency problem for end user applications where short turnaround times are critical. This is where edge computing comes in with data that is processed on algorithms stored locally on the edge device. In other words, machine learning is now decentralized and round trips to compute-heavy backend servers are reduced. Increased connectivity in mobile devices with 4G/5G and cameras purpose built for computer vision allow these edge devices to act as “machine learning agents” that can run computer vision algorithms at the edge.
In combination with the AI chips discussed above, commercializing computer vision algorithms through edge computing is becoming a reality.
MLOps
Just addressing the four drivers of computer vision is not enough to commercialize. They have to be stitched together and leveraged appropriately through processes and pipelines. Enter MLOps.
MLOps describes the process of taking an experimental machine learning model into a production system. It consists of three main phases: ML, Dev, and Ops (and hence contracted to MLOps); the ML phase involves writing the model and dataset curation; the Dev phase involves packaging the model and integrating it into a platform or service; and the Ops platform involves installation and service in production for customers using the models.
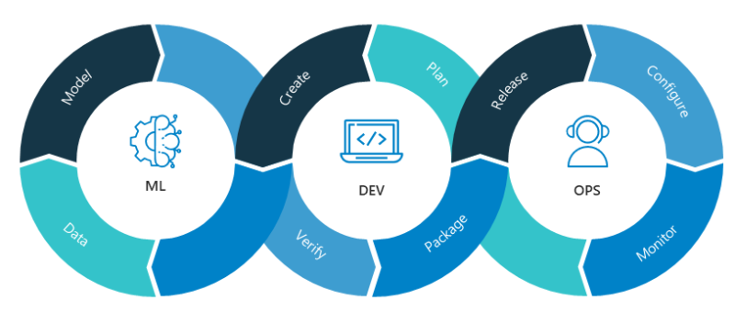 The MLOps Model
The MLOps Model
Image credit: Nvidia
Through MLOps and the four drivers of computer vision commercialization, deployment times and costs for machine learning models into production can dramatically decrease.
According to Nvidia researchers, MLOps is similar to DevOps, with a team of data scientists added to the mix. The job of data scientists is to write models and curate the dataset. The latter is a much larger and time-consuming task, partially because the type, abundance, and structure of the data can influence the results of the machine learning model, ultimately making the quality of the product rely heavily on training data.
As machine learning models become more advanced, the Dev team of the MLOps system needs to be able to package it into a product that can run on different types of devices while minimizing data usage, battery usage, and compute power. Extremely large and complicated models may provide the best insights, but they could lack the efficiency needed for industry applications. The Dev and ML teams can work together to accomplish the first two drivers of computer vision commercialization.
Commercial computer vision
A well-known example of a company using MLOps to deploy computer vision models in their product is Tesla. With Full Self Driving (FSD), Tesla aims to solve the self-driving problem by integrating AI-optimized silicon chips into every car model, using sensor-fusion and computer vision to solve perception and control problems, and developing core algorithms to take machine learning results and apply it to car movements and real-world perceptions. Andrej Karpathy, head of AI at Tesla, mentions that Autopilot neural networks, “involve 48 networks that take 70,000 GPU hours to train over 10M+ images/videos.” Andrej recently announced that they built an in-house supercomputer with 5760 GPUs used to train their 1.5 petabyte sized data set, and is the 5th largest supercomputer in the world. They optimized their data collection through their fleet of cars, built their own chips for heavy machine learning workloads, and interfaced it nicely within the cars.
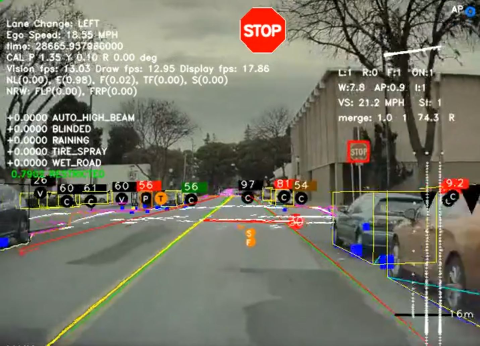 Tesla FSD Front Camera View
Tesla FSD Front Camera View
Image Credit: Tesla
Tesla is a good example of MLOps in action and how they’ve taken experimental computer vision models and implemented them into real world scenarios.
One of the more innovative ways companies have been commercializing computer vision algorithms is in the autonomous retail store space. One major player is a Cervin portfolio company AiFi that is focused on automating retail stores using a computer vision-only based approach to track hundreds of customers as they browse through thousands of products in a store, pick up items and walk out with them without stopping at a cashier. Such a scale with high accuracy is unprecedented in computer vision commercialization.
 An AiFi-enabled autonomous store
An AiFi-enabled autonomous store
Image Credit: AiFi
The problem is as technically difficult as self-driving cars given the requirement of high accuracy. AiFi uses simulation to generate training and testing dataset with pixel-perfect ground truth efficiently to boost computer vision accuracy and commercialization speed. They have focused on the four drivers but had to overcome several problems, all of which were solved with some elements of MLOps.
From a ML algorithm standpoint, multiple models had to be created in order to track products on a shelf for planogram (layout of products) management, customer movement throughout the store, and probability maps for items on a shelf that were selected. AiFi uses different techniques to address the data abundance problem, even including some store simulation-based approaches.
 AiFi’s shopper tracking simulation
AiFi’s shopper tracking simulation
Image Credit: AiFi
The data scientists and development team at AiFi work together to deploy ML models to different stores in different locations. AiFi is an excellent example of how MLOps can transform computer vision and machine learning companies that lack the resources of a big tech firm into a thriving business that has stores deployed all over the world.
Bringing it all together
Exciting innovations in the four drivers of commercialization in combination with advances in MLOps allow for cost-effective and seamless deployment of machine learning algorithms. Computer vision commercialization is rapidly gaining traction as the next big wave, driving great impact globally.
------------------
Acknowledgements
A special thank you to Devin Shah for the research and Ying Zheng and Chandra Khatri for their reviews.






